Do talk back: creating conversation in computers
Students and experts in the field of natural language processing help computers understand us. Erin Malsbury talks with experts about the current limitations and future of the field. Illustrated by Erin Malsbury.

Illustration: Erin Malsbury
If you’ve ever tried learning a new language, you know how complex human speech is. You probably needed to learn new synonyms, new words with multiple meanings and maybe even new ways to structure sentences. Now, imagine that your first language is not made up of words at all. Rather than using syllables and synonyms, you interpret the world through numbers. Learning a new language would seem nearly impossible, and even translation would become a puzzle. Such is the case for computers, digital machines that break everything down into 1s and 0s.
From personalized web searches and advertisements to translation services, “Under the hood, it’s all natural language processing.”
So, how is it that when we tell Siri to set an alarm for 6 am, we don’t sleep through our morning meeting? Or, when we ask Alexa to play us a Queen song, we end up belting Bohemian Rhapsody rather than sitting in awkward silence? From language translation to simple Google searches, we increasingly expect computers to interpret what we say and respond appropriately.
Natural language processing helps computers meet our expectations by training them to process and respond to normal human speech. Still in its infancy, the field blends computer science with linguistics and psychology and has the potential to make our lives much easier.
The field of natural language processing helps computers meet our expectations by training them to process and respond to normal human speech. Researchers at the University of California, Santa Cruz are currently exploring the possibilities and challenges of using natural language with computers through research, a competitive “socialbot” building team, and a new natural language processing master’s program.

Natural language processing combines elements of computer science, psychology and linguistics.
From personalized web searches and advertisements to translation services, “Under the hood, it’s all natural language processing,” says Amita Misra, an IBM Watson researcher who works on algorithms that predict the sentiment of texts. She earned her PhD at UC Santa Cruz under the mentorship of a leading computer dialogue generation expert, Marilyn Walker.
Walker, who has taught and conducted research at UC Santa Cruz since 2009, grew up sandwiched between two dialects in Ohio, in a linguistic boundary called an isogloss. North of her, people spoke in a Northern Midland dialect, and to the South, in an Appalachian Midland dialect. Some of her neighbors pronounced the word route as “rowt”, while others pronounce it as “root”. These types of details instilled in her an early fascination with the complexity of spoken communication. In college, Walker became interested in artificial intelligence and jumped at the chance to combine it with her interest in communication in the subfield of natural language processing.
After graduate school, Walker experimented with using machine learning methods to help computers construct meaningful dialogue at AT&T Bell Labs. When she moved into academia at the University of Sheffield in England, Walker began working to create socialbots that express different personalities according to the speech of the person using the system. Based on psychology findings that people with different personalities use words differently, the socialbot would recognize a user’s personality traits based on certain keywords, then adapt to that person. “That was a tremendous amount of fun,” says Walker with a smile.
Walker was ahead of the curve. “At the time, industry never would have funded me to actually work on an expressive bot that had its own personality,” she says. “But now, that’s something that people are starting to be very interested in.” Some customer service chats, for example, now change the tone of the dialogue in response to the words that customers use.
The field’s beginnings
Natural language processing’s roots began with British mathematician Alan Turing’s famous paper, “Computing Machinery and Intelligence,” published in 1950. In the paper, Turing considers whether it is possible for machines to act like thinking individuals. He outlines an “imitation game,” now called the Turing Test, to assess the intelligence of a digital machine. The machine passes the Turing Test if it can hold a written conversation with a human without that person realizing that they are talking to a machine. Turing published the paper at a time when computers were still rudimentary, one-task machines, but he argued that a “learning machine” would be able to play the game successfully.
In 1966, MIT professor Joseph Weizenbaum created the first chatbot — a computer program that converses back and forth with users — capable of attempting the Turing test. The program, named ELIZA, imitates a therapist by picking out keywords in the sentences of users and spitting out a pre-programmed, open-ended question. ELIZA can’t understand words or context, which sometimes results in comical ad nauseam dialogue. (Try a version of it yourself.)
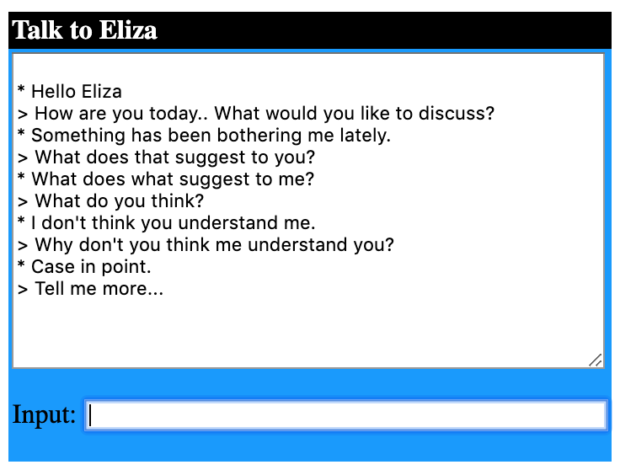
A conversation with a modern version of Eliza
Weizenbaum created the program in part to highlight the superficial nature of interactions between humans and machines, but ironically, many users grew fond of ELIZA and believed the program could truly understand what they told it. People became so attached to the program that the term “ELIZA effect” now refers to anthropomorphism in computer science.
Clever dialogue generation might lead people to believe a machine understands what they are saying, [but a computer can spit out text without any understanding]. When the discussion veers in an unexpected or complicated direction—as human interactions often do—the conversation breaks down. Without advancements in natural language understanding, machines will continue to generate stiff responses and remain just as incapable of dynamic conversations as ELIZA was over 50 years ago.
The Alexa Prize Challenge
Creating fluid dialogue remains one of the most difficult problems in natural language processing. Researchers and graduate students around the world search for creative solutions in Amazon’s Alexa Prize Challenge. In the annual competition, ten university teams from around the world must build “socialbots.” Any of Amazon’s thousands of Echo smart speaker users can converse with the socialbots by saying “Alexa, let’s chat.” The goal is to build a bot capable of holding a coherent conversation for 20 minutes about anything the user wants to talk about — a task that experts say is currently almost impossible.
“Language is complex,” says Misra. “If you take a simple example of when I say the word ‘bank,’ you need a lot of context… it could be a bank of a river, it could be a financial institution, or I could say, ‘I can bank upon you.’” Without context and understanding, conversations fail.
Misra participated in the first Alexa Prize Challenge in 2017 while she was a PhD student at UC Santa Cruz. She says the problem is so challenging that the judges currently focus not on whether the teams actually achieve the goal, but how they approach the issue in the first place. For example, one major decision that teams face is how much of the socialbot’s dialogue to [design by hand]preprogram — known as handcrafting — and what to leave to machine learning.
The team with the best socialbot wins $500,000. If the team achieves the “grand challenge” of creating a bot that can converse “coherently and engagingly” for 20 minutes with an average user rating of 4.0 out of 5.0, the team wins a $1million research grant. No team has come close to winning this grand prize so far.
A panel of Amazon employees selects participating teams based on the novelty and potential scientific contribution of the approach they plan to use. The “Athena team” from Marilyn Walker’s lab has qualified and competed all three years that the competition has existed. Walker says the most novel part of what her team is trying to do is “to get away from scripted or ‘call flow’ dialogue management,” in which socialbots rely on a pre-determined script. Her team’s new methods for generating dialogue assemble sub-dialogues about individual subjects “to make a novel and extended conversation on a topic,” she says. In this strategy, an algorithm helps one main dialogue manager decide which of several specific “response generators” gets to control the conversation for a few responses. The result, they hope, will flow more like a real interaction between two people.
Today’s tech
The state-of-the-art method that most researchers are currently excited about, called deep learning, is difficult to incorporate into a competition like the Alexa Prize Challenge. Deep learning uses “deep neural networks” — webs of interconnected algorithms inspired by the billions of neurons within our brains. “I’m really the most amazed by the advancement of deep learning,” says Zhichao Hu, one of Walker’s former PhD students who now works as a software engineer at Google. “I’ve really seen deep learning make a grand entrance and help push the field into a place where it has never been.”
Deep learning techniques become more accurate as they receive more data, but they require large amounts of “training data” pre-annotated by humans to work. They also rely on huge amounts of computing power. The immense resource requirements limit teams’ abilities to use these techniques in a project like the Alexa Prize Challenge. For most cutting-edge work, researchers can pour enormous amounts of time, energy and training data into one small piece of the language generation puzzle. But for the Alexa Prize Challenge, teams don’t isolate any single part of the process. They must focus broadly on the entire socialbot. And although researchers have high hopes for neural networks, they don’t yet consistently produce dialogue that is high quality enough to use in a customer-facing competition.
Still, Walker says this year’s team is interested in using a neural natural language generator for one aspect of its social-bot: to have conversations about video games. Jurik Juraska, a UCSC PhD student working on the language generator, says the model can produce single “utterances” but not carry on a full conversation. “The conversation example as a whole is more of a goal that we strive for, rather than something our system can achieve at the moment,” says Juraska. The model still needs to be able to take into account the “context of previous turns in the conversation,” he says. Below is an example of the dialogue, with the system represented by S and the human user represented by U.

A snippet of dialogue from UCSC’s socialbot
Emily Bender, a computational linguist from the University of Washington in Seattle, says that language modeling — that is, using training data to calculate how often certain words appear together and constructing sentences with that information — is not synonymous with context-based understanding. Good language models might create grammatically correct sentences that put verbs after nouns and articles in the right places, but without an understanding of context and what those words signify to people, the language model might still create gibberish.
“I think the big challenge right now is coming up with tasks that push the field in the direction of language understanding,” she says. Bender doesn’t think “more and more computing and bigger and bigger language models,” address the underlying issue of teaching machines the subtleties of context. Bender says although deep learning is exciting and powerful, it’s just the engine behind these big [language models]. “I would love to see people applying deep learning in ways that connect more with an understanding of the shape of the problem of how languages work—how language understanding works.”
Walker says she finds this challenge both frustrating and amusing. The Athena team tried training its social bot to recognize movie names but found that even after they provided it with lists of titles, the bot could not always tell the difference between the movie names and other speech. “There’s a movie named ‘Her’, right?” says Walker. “We discovered there’s also a movie named, like, ‘How are you?’, and there’s a movie named ‘I’.” Walker chuckles and shakes her head. “You actually have to really have a very good understanding of how it’s being used in the context of a conversation to figure out whether it’s likely that it actually is being used as a movie name.” Most chatbots wouldn’t be able to tell.
Not quite there yet
Almost any Siri or Alexa user could confirm that the possible conversations with these voice assistants are limited — and sometimes bad enough to warrant #AlexaFails tweets like the one below — but people still assume that artificial intelligence technology is more advanced than it actually is.
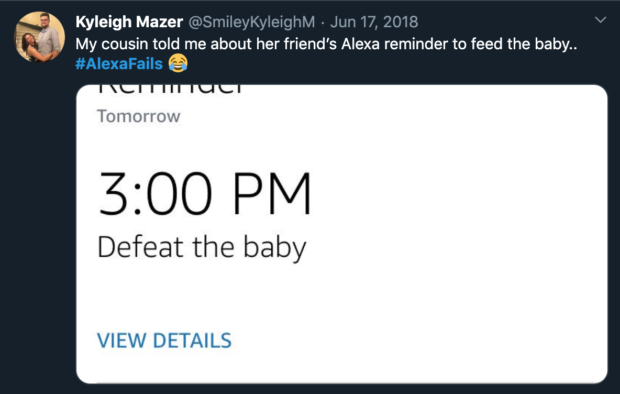
#Alexafails on Twitter reveals comedic blunders of the smart speaker.
Representations of human-like computers dominate films ranging from “Her”, in which a lonely man falls in love with his artificial virtual assistant, to the “Terminator” series, in which humanity struggles in a war against machines. Some audiences think these fictional characters are close to reality, and the lack of transparency that clouds some corners of the tech world doesn’t help. In 2016, Hong Kong-based Hanson Robotics unveiled Sophia, an eerily human-like robot, complete with quips and changing facial expressions. Sophia addressed the United Nations in 2017 and was even granted citizenship in Saudi Arabia. Awarding symbolic rights to a robot sparked outrage in a country where, less than a month before, women were banned from driving.
In the face of public speeches and honorary citizenships, researchers argue that Sophia’s creators misled the public about what is currently possible in artificial intelligence. Yann Lecun, Facebook’s head of artificial intelligence research, for example, tweeted that the robot is “complete bullsh*t” and called it a puppet. Sensationalization like the excitement that surrounds Sophia makes it hard for people outside the field to understand how far current technologies truly are from making computers with human-like intelligence, say experts such as Misra. She emphasizes that “there’s a long, long way to go” before computers will understand human language.
The road ahead
Walker remains undeterred, and she sees opportunity in the complexity of language. “It leads to this incredible richness in the field,” she says. “There’s this kind of abundance of new things that people keep coming up with all the time that you can do with natural language processing.” Aside from personal assistants, searches and translation, natural language processing can be used for customer service chat bots, data analysis and text suggestion. For instance, Google’s Gmail now automatically suggests common email phrases as replies. Grammarly, another popular web service, uses natural language processing to give users suggestions about grammar and tone.
As the market for computer dialogue research explodes, Walker is making sure UC Santa Cruz grows with it. In the fall of 2020, the university will welcome new master’s students into a one-year natural language processing-focused program. The master’s program is geared towards students who have a general computer science background and want to learn more about natural language processing specifically. A traditional computer science master’s program might only include two or three natural language processing classes total, so when companies search for potential employees who are familiar with the subject, they tend to hire people with more specific knowledge from PhD programs. The new master’s program could make the field more accessible.
“I think that will really open up opportunities for new students that are interested in this field,” says Google software engineer Zhichao Hu. “It’s a popular and very practical field right now.”
Walker hopes the program will draw a diverse group of students. Natural language processing, with its ties to psychology and linguistics, has traditionally consisted of a more diverse and gender-inclusive group of experts than other fields within computer science. “That’s one thing that’s always made me feel more at home in the field,” says Walker.
And a diverse group of experts working in natural language processing is not only desirable: it’s necessary. Misra at IBM Watson says one aspect of the field that must grow is bias correction. “Machines are learning only what we feed them,” she says. That means they often learn associations and patterns from Wikipedia articles and social media posts, such as tweets. (One artificial intelligence engine at Google also gets trained on thousands of romance novels that software engineers say will help its dialogue sound more casual.) “Whatever mathematical representation they learn, they learn it from the articles we write,” Misra says. “So if there is a human bias in society, then machines will learn it too.” She highlights a famous example of a computer learning to associate the word doctor with the word man and nurse with woman.
Bender at the University of Washington agrees that researchers need to pay attention to the biases training data introduce. “We’re taking large collections of things that particular people, with their own particular cultural positions and biases, have said,” she explains.
Researchers are still looking for a solution, but Misra insists that before artificial intelligence is used to inform decisions, people must spend more time addressing these issues. She envisions a world where users can someday truly converse with virtual assistants like Alexa and “learn some of the viewpoints and arguments that the machine has learned from others.” In a culture of intense division, Misra sees it as a potential way to find middle ground.
“That’s far away from where we stand today,” she says. “But I think if we could really have that kind of thing… that’s something that can have a great impact on society.”
© 2020 Erin Malsbury / UC Santa Cruz Science Communication Program

Erin Malsbury
Author and Illustrator
B.S. (ecology) A.B. (anthropology) University of Georgia
Internships: Monterey Herald, Science, California Sea Grant, Smithsonian National Museum of Natural History
A friend and I once brought identical stuffed wolves to second grade. She said they should have pups. So I, having just learned about life’s origins, eagerly shared with my classmates what I thought was innocent science.
My mini-lecture on mating drew the wide-eyed attention of nearly every student before my teacher overheard. With her eyes wide for a different reason, she denounced my crash course as inappropriate. I learned then that communicating facts can be complicated.
Later, as an ecology and anthropology student, I channeled my love for communication into environmental outreach and teaching. As my zeal for explaining ecology to pre-med students and school groups grew, I searched for ways to engage larger audiences.
Through journalism, I now hope to make science accessible to everyone, from unabashed second-graders to their flabbergasted teachers.
There are various sports betting apps readily available to download and play
on, depending on the state you live in.
Comecei recentemente a usar o Office 2021 e, até agora, tenho ficado impressionado.
As novas funcionalidades são bastante impressionantes.
A minha parte favorita é a funcionalidade X . Para resumir, penso que é uma excelente atualização .
Исключительно индивидуальноприятно
веб-сайт. Поразительный информация предлагаемый несколько переход к.
Посетите также мою страничку 1вин казино
This article is genuinely a good one it assists
new net viewers, who are wishing for blogging.
Recognizing the UK Teatime Lotto game results today is vital for
those keen on leveraging historical fads and statistical insights to enhance their opportunities of success.
Great blog here! Additionally your site a lot up very fast!
What host are you the use of? Can I am getting your affiliate link in your host?
I wish my website loaded up as quickly as yours lol
Remarkable things here. I’m very happy to peer your
post. Thanks so much and I am having a look ahead to contact you.
Will you kindly drop me a e-mail?
Hmm it looks like your blog ate my first comment (it was extremely long)
so I guess I’ll just suum it up what I rote and say, I’m
thoroughly enjoying your blog. I too am an aspiring blog blogger
but I’m still new to thhe whole thing. Do you have any points for rookie blog writers?
I’d genuinely appreciate it.
Allso visit mmy web page – Melvina
Yay google is my king helped me to find this great web site!
Приветствуем вас на нашем веб-сайте!
Здесь вы найдёте всё необходимое
для успешного управления своими финансами.
Мы предлагаем широкий спектр финансовых продуктов, которые помогут вам достичь ваших целей и обеспечить
стабильность в будущем.
В нашем ассортименте представлены различные виды банковских продуктов,
инвестиции, страхование, кредиты и многое
другое. Мы постоянно обновляем нашу базу данных, чтобы вы всегда были в курсе последних тенденций и
инноваций на финансовом рынке.
Наши специалисты помогут вам выбрать наиболее подходящий продукт,
учитывая ваши индивидуальные
потребности и предпочтения. Мы предоставляем консультации и рекомендации, чтобы вы могли принять обоснованное решение и избежать возможных
рисков.
Не упустите возможность воспользоваться нашими услугами
и откройте для себя мир финансовых возможностей!
Заходите на наш сайт, ознакомьтесь с каталогом продуктов и начните свой
путь к финансовой стабильности
прямо сейчас!
дебетовая карта с функцией овердрафта без комиссии